
Porfolio With Python 4
Updated:

평균-분산 포트폴리오 이론
# 경기 국면별 확률과 주식 기대수익률을 리스트로 저장한다.
stock_a = [0.09, 0.05, 0.03]
stock_b = [0.22, -0.09, 0.05]
prob = [1/3, 1/3, 1/3]
# 주식 a와 b의 경기 국면에 따른 수익률 기댓값을 저장할 변수를 준비한다.
ex_a = 0.0
ex_b = 0.0
wgt_a = 0.5
wgt_b = 0.5
# 주식 a와 b의 기댓값을 구한다. 기대수익률과 경기 국면별 확률을 곱한 합계를 구한다.
# 기대수익률과 경기 국면별 확률 리스트를 zip()함수로 묶어 반복한다.
for s, p in zip(stock_a, prob):
ex_a = ex_a + s * p
for s, p in zip(stock_b, prob):
ex_b = ex_b + s * p
# 포트폴리오의 기대수익률은 투자 비중과 각 자산의 기대수익률을 곱해 합친 것이다.
ex_p = wgt_a * ex_a + wgt_b * ex_b
print('주식 A의 기대수익률은 {:.2%}'.format(ex_a), '\n')
print('주식 B의 기대수익률은 {:.2%}'.format(ex_b), '\n')
print('포트폴리오의 기대수익률은 {:.2%}'.format(ex_p))
주식 A의 기대수익률은 5.67%
주식 B의 기대수익률은 6.00%
포트폴리오의 기대수익률은 5.83%
- 위의 기대수익률을 행렬 연산으로 구해본다.
# numpyl library를 np 라는 이름으로 import 한다.
import numpy as np
# numpy의 matrix 클래스를 사용해 국면별 확률을 1x3 행렬로 만든다.
prob = np.matrix([[1/3, 1/3, 1/3]])
# 주식 A와 B의 수익률을 1x3 행렬로 만든다.
stock_a = np.matrix([[9, 5, 3]])
stock_b = np.matrix([[22, -9, 5]])
# 행렬 곱하기 연산을 수행한다. 단, 행렬의 차원이 맞아야 하므로 stock_a.T, stock_b.T와 같이 행렬을 전치 시켜준다.
# 따라서 prob는 1x3, stock_a와 stock_b는 3x1 행렬이 돼 곱하기 연산의 결과 1x1의 결과 행렬이 나오게 된다.
ex_a = prob * stock_a.T
ex_b = prob * stock_b.T
# %.2f는 %로 연결한 변수(%ex_a와 %ex_b)의 서식을 지정하는 것으로, 소수점 이하 두 자리 실수로 출력한다.
print('주식 A의 기대수익률은 %.2f%%'%ex_a)
print('주식 B의 기대수익률은 %.2f%%'%ex_b)
# 개별 주식의 기대수익률을 계산했으므로 두 개 주식으로 구성된 포트폴리오의 기대수익률을 계산할차례다.
# weight는 투자 비중을 가리키는 1x2 행렬이다.
weight = np.matrix([[0.5, 0.5]])
# '투자 비중 * 주식 기대수익률'이라는 행렬 연산을 위해 앞서 구한 각 주식의 기대수익률을 1x2 행렬로 만든다.
# 그런데 ex_a와 ex_b는 1x1 행렬이므로 그대로 사용해 행렬을 만들면 행렬 속 행렬인 셈이므로 이를 스칼라값으로 바꿔준다.
# numpy.asscalar() 함수는 1x1 행렬을 스칼라 값으로 변환해준다.
ex_ab = np.matrix([
[np.asscalar(ex_a), np.asscalar(ex_b)]
])
# 투자 비중 * 주식 기대수익률이라는 행렬 연산을 한다. 다만 둘 다 1x2 행렬이므로 ex_ab의 행렬을 전치해 행렬 곱을 계산한다.
ex_p = weight * ex_ab.T
print('포트폴리오의 기대수익률은 %.2f%%'%ex_p)
주식 A의 기대수익률은 5.67%
주식 B의 기대수익률은 6.00%
포트폴리오의 기대수익률은 5.83%
- 주식 A와 B 그리고 포트폴리오의 분산과 표준편차를 구해보자.
# sqrt 함수를 사용하기 위해 math 모듈을 import 한다.
import math
# 경기 국면별 확률과 주식 기대수익률을 리스트로 저장한다.
stock_a = [0.09, 0.05, 0.03]
stock_b = [0.22, -0.09, 0.05]
prob = [1/3, 1/3, 1/3]
# 주식 a와 b의 경기 국면에 따른 수익률 기댓값을 저장할 변수를 준비한다.
ex_a = 0.0
ex_b = 0.0
# 주식 a와 b의 기댓값을 구한다. 기대수익률과 경기 국면별 확률을 곱한 합계를 구한다.
# 기대수익률과 경기 국면별 확률 리스트를 zip()함수로 묶어 반복한다.
for s, p in zip(stock_a, prob):
ex_a = ex_a + s * p
for s, p in zip(stock_b, prob):
ex_b = ex_b + s * p
# 분산을 저장할 변수와 투자비중을 미리 준비한다.
var_a, var_b, wgt_a, wgt_b = 0.0, 0.0, 0.5, 0.5
# 리스트 stock_a와 prob에서 각각 데이터를 변수 s와 p로 받아 반복한다.
for s, p in zip(stock_a, prob):
var_a = var_a + p * (s - ex_a) ** 2
for s, p in zip(stock_b, prob):
var_b = var_b + p * (s - ex_b) ** 2
print('주식 A의 분산은 {:.2%}'.format(var_a), '\n')
print('주식 B의 분산은 {:.2%}'.format(var_b))
주식 A의 분산은 0.06%
주식 B의 분산은 1.61%
# 포트폴리오의 분산을 계산한다.
# 공분산, 분산, 표준편차를 계산한다.
cov = sum(p * (a - ex_a) * (b - ex_b) for a, b, p in zip(stock_a, stock_b, prob))
var_p = wgt_a ** 2 * var_a + wgt_b ** 2 * var_b + 2 * wgt_a * wgt_b * cov
std_p = math.sqrt(var_p)
print('포트폴리오의 분산은 {:.2%}'.format(var_p), '\n')
print('포트폴리오의 표준편차는 {:.2%}'.format(std_p))
포트폴리오의 분산은 0.53%
포트폴리오의 표준편차는 7.26%
- 수정주가
- 주식 한 주의 가격과 회사가 발행한 그 주식의 총수를 곱한 것이 시가총액이다.
수정주가는 이러한 액면변경, 유무상증자 등과 같은 이벤트를 주가에 반영해 현재 주가의 수준을 과거와 비교할 수 있도록 과거 주가도 함께 수정하는 것을 말한다. 정확하게 분석하려면 종가 대신 수정주가를 사용해야 한다.
- 주식 한 주의 가격과 회사가 발행한 그 주식의 총수를 곱한 것이 시가총액이다.
# pandas_datareader 설치
!pip install pandas_datareader
# 실제 미국 주식 데이터를 이용한 포트폴리오 기대수익률
# Library import
import numpy as np
import pandas as pd
from pandas_datareader import data as web
import random
# 몇 가지 종목 코드를 갖고 포트폴리오에 포함된 주식 리스트를 만든다
tickers = ['BA', 'AAL', 'DAL', 'UAL', 'LUV', 'ALK']
# 수정주가를 담을 빈 데이터프레임을 미리 준비한다.
adjClose = pd.DataFrame()
# for loop를 만들어 tickers 리스트를 반복하면서 종목 코드를 꺼내고
# DataReader 함수를 사용해 수정주가 데이터를 내려받는다.
# 데이터는 야후 파이낸스를 통해 얻는다.
for item in tickers:
adjClose[item] = web.DataReader(item, data_source='yahoo', start='15-09-2018')['Adj Close']
# pandas의 pct_change 함수는 데이터의 변화량을 %로 계산한다.
# 일간 수정주가 데이터를 일간수익률로 변환해 dailySimpleReturns에 저장한다.
dailySimpleReturns = adjClose.pct_change()
# 기대수익률 대신 일간수익률의 평균을 계산한다.
# 계산 결과는 np.matrix() 함수를 사용해 행렬로 변환한 후 행렬 연산에 사용한다.
meanReturns = np.matrix(dailySimpleReturns.mean())
# 주식의 개수만큼 투자 비중을 만든다.
numAssets = len(tickers)
# 투자 비중은 난수로 만들고 투자 비중을 비중의 합으로 나눠 투자 비중의 합이 1.0이 되도록 만든다.
weights = np.random.random(numAssets)
weights = weights / sum(weights)
# 투자 비중과 연간 환산수익률을 곱해 포트폴리오 기대수익률을 계산한다.
# weights와 meanReturns의 차원은 1x6이다.
# 행렬의 곱셈 연산을 위해 meanReturns 행렬을 전치한다.
portReturnsExpected = np.sum(weights * meanReturns.T)
print(portReturnsExpected)
4.366383912513196e-05
# 포트폴리오의 분산을 구해보자.
# 위의 코드를 받아와서 사용할 것이다.
# 행렬 연산을 위해 weights를 matrix 데이터형으로 변환한다.
weights = np.matrix(weights)
# dailySimpleReturns는 pandas의 DataFrame 객체다. 데이터형을 확인하기 위해 type() 함수를 사용했다.
print('dailySimpleReturns의 데이터형: ', type(dailySimpleReturns))
# DataFrame 객체는 공분산을 계산해주는 cov 함수를 제공한다.
# cov 함수는 DataFrame을 돌려준다. 이번에도 데이터형을 확인하기 위해 type() 함수를 사용했다.
print('dailySimpleReturns.cov() 결과의 데이터형: ', type(dailySimpleReturns.cov()))
# cov() 함수로 공분산한 결과는 DataFrame이다. 이 결과는 다시 행렬 연산을 위해 변환할 것이다.
# 그러므로 별도의 변수로 저장하지 않고 바로 values 함수를 사용해 행렬로 변환하고 이를 pcov 변수로 저장한다.
pcov = dailySimpleReturns.cov().values
# 행렬 연산으로 분산을 계산한다. 즉, [비중 x 공분산 행렬 x 비중의 전치행렬]의 연산을 숭행해 포트폴리오의 분산을 varp 변수에 저장하고 출력한다.
varp = weights * pcov * weights.T
print('포트폴리오 분산은', varp)
dailySimpleReturns의 데이터형: <class 'pandas.core.frame.DataFrame'>
dailySimpleReturns.cov() 결과의 데이터형: <class 'pandas.core.frame.DataFrame'>
포트폴리오 분산은 [[0.00120292]]
- 이번에는 여섯 개 주식의 1년치 수정주가를 갖고 비중을 달리하는 수만 개의 포트폴리오를 만들어 효율적 투자선을 구현해보자
# Library import
import numpy as np
import pandas as pd
from pandas_datareader import data as web
import matplotlib.pyplot as plt
import matplotlib as mlp
# 여섯 개 종목(보잉, 아메리카에어라인, 델타에어라인, 유나이티드에어라인, 사우스웨스트에어라인, 알래스카에어라인)
# 위의 여섯 개 종목을 가지고 비중을 무수히 바꿔 포트폴리오를 만들 것이다.
tickers = ['BA', 'AAL', 'DAL', 'UAL', 'LUV', 'ALK']
# 수정주가를 저장할 데이터프레임 변수(adjClose)를 미리 만들어둔다.
pxclose = pd.DataFrame()
# for loop로 여섯 개 종목을 반복하면서 야후 파이낸스에서 일간 주가 데이터를 가져온다.
for t in tickers:
pxclose[t] = web.DataReader(t, data_source='yahoo', start='01-01-2020', end='31-12-2020')['Adj Close']
pxclose.head()
| BA | AAL | DAL | UAL | LUV | ALK | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2019-12-31 | 323.833313 | 28.574404 | 58.078648 | 88.089996 | 53.773045 | 67.367950 |
| 2020-01-02 | 331.348572 | 28.982893 | 58.634808 | 89.739998 | 54.629749 | 67.785583 |
| 2020-01-03 | 330.791901 | 27.548195 | 57.661533 | 87.900002 | 54.141628 | 66.542633 |
| 2020-01-06 | 331.766083 | 27.219410 | 57.264275 | 87.699997 | 53.922474 | 66.224434 |
| 2020-01-07 | 335.285156 | 27.119778 | 57.214619 | 86.769997 | 54.081860 | 65.806808 |
# 종가의 수익률을 계산한다.
ret_daily = pxclose.pct_change()
ret_daily.head()
| BA | AAL | DAL | UAL | LUV | ALK | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2019-12-31 | NaN | NaN | NaN | NaN | NaN | NaN |
| 2020-01-02 | 0.023207 | 0.014296 | 0.009576 | 0.018731 | 0.015932 | 0.006199 |
| 2020-01-03 | -0.001680 | -0.049502 | -0.016599 | -0.020504 | -0.008935 | -0.018337 |
| 2020-01-06 | 0.002945 | -0.011935 | -0.006889 | -0.002275 | -0.004048 | -0.004782 |
| 2020-01-07 | 0.010607 | -0.003660 | -0.000867 | -0.010604 | 0.002956 | -0.006306 |
# 종가수익률 평균에 250을 곱해서 영업일의 기대수익률을 만든다.
ret_annual = ret_daily.mean() * 250
# 일간수익률의 공분산을 계산하고 연간 단위로 만든다.
cov_daily = ret_daily.cov()
cov_annual = cov_daily * 250
cov_annual.head()
| BA | AAL | DAL | UAL | LUV | ALK | |
|---|---|---|---|---|---|---|
| BA | 0.758444 | 0.577586 | 0.551309 | 0.683370 | 0.399857 | 0.527603 |
| AAL | 0.577586 | 1.076424 | 0.708576 | 0.903706 | 0.473499 | 0.642033 |
| DAL | 0.551309 | 0.708576 | 0.642466 | 0.764864 | 0.423953 | 0.560710 |
| UAL | 0.683370 | 0.903706 | 0.764864 | 1.061098 | 0.523715 | 0.714048 |
| LUV | 0.399857 | 0.473499 | 0.423953 | 0.523715 | 0.386287 | 0.416127 |
# 포트폴리오 수익률, 변동성, 투자 비중을 저장할 변수를 미리 준비한다.
p_returns = []
p_volatility = []
p_weights = []
# len() 함수로 투자자산의 수를 계산한다.
n_assets = len(tickers)
# 여섯 개 종목으로 투자 비중을 바꿔 5만 개의 포트폴리오를 만들 것이다.
n_ports = 50000
# n_ports만큼 반복하면서 자산의 투자 비중을 랜덤하게 만들고 포트폴리오의 기대수익률, 변동성을 계산한다.
# 계산한 수익률, 변동성, 투자 비중은 앞서 미리 준비한 변수, p_returns, p_volatility, p_weights에 저장한다.
for s in range(n_ports):
# np.random.random() 함수로 난수 생성
wgt = np.random.random(n_assets)
# 투자 비중 합계 100%를 위해 각 난수를 난수 합으로 나눈다.
wgt /= np.sum(wgt)
# 투자 비중 * 기대수익률로 기대수익률 계산
ret = np.dot(wgt, ret_annual)
# 변동성 계산
vol = np.sqrt(np.dot(wgt.T, np.dot(cov_annual, wgt)))
# 계산한 수익률 추가
p_returns.append(ret)
# 변동성 추가
p_volatility.append(vol)
# 투자 비중 추가
p_weights.append(wgt)
# 완성된 5만 개의 포트폴리오를 차트로 그린다.
# np.array로 변환한다.
p_volatility = np.array(p_volatility)
p_returns = np.array(p_returns)
# 색상을 n_ports만큼 만든다.
colors = np.random.randint(0, n_ports, n_ports)
# Matplotlib는 차트에 대한 여러가지 스타일을 지정할 수 있다.
plt.style.use('ggplot')
# 분산차트 설정
plt.scatter(p_volatility, p_returns, c=colors, marker='o')
# x축 이름
plt.xlabel('Volatility (Std. Deviation)')
# y축 이름
plt.ylabel('Expected Returns')
# 차트 제목
plt.title('Efficient Frontier')
plt.show();
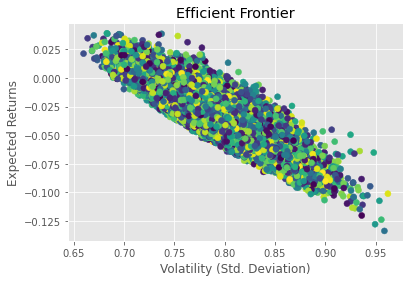
- 일단 기본적으로 포트폴리오를 만든 6개의 종목이 항공사 주로 코로나에 굉장한 영향을 받은 종목들이다.
- 그러므로 수익률이 굉장히 안좋은 모양을 볼수 있다.
- 효율적 포트폴리오를 만들어 투자를 한다고 해도 65%의 위험을 가져도 겨우 2.5%정도의 수익을 얻는걸로 보아 좋지 않은 포트폴리오라고 할 수 있다.
Leave a comment