
Porfolio With Python 2
Updated:

1. 자주 사용하는 통계량 : 기댓값, 분산, 공분산, 상관계수
1.1 평균과 기댓값
- 보통 평균이라고 하면 산술평균을 가리키는데, 산술평균은 모든 자료 값을 더한 합계를 자료 개수로 나눈 값이다.
- 기댓값은 확률이 더해진 평균이다. 즉, 데이터 원소와 이에 대한 확률값을 곱해 더한 것이다.
- 정리하자면 평균은 확률을 특별히 고려하지 않은 것이다. 즉, 확률적인 개념이 없을 때 쓰인다.
기댓값은 사건이 일어날 것으로 예상되는 확률값이다.
따라서, 확률 개념이 들어가는 통계에서 대부분 ‘평균’이라는 표현으로 사용되기보다는 ‘기댓값’이라는 표현으로 사용된다.
# numpy 라이브러리르 임포트한다.
import numpy as np
# array() 함수로 list를 array 객체로 저장한다.
a = np.array([1, 2, 3, 4, 5, 6])
# 객체의 mean() 함수를 사용해 평균을 계산한다.
print(a.mean())
3.5
- 기댓값을 계산하려면 사건과 사건이 일어날 확률을 가진 리스트가 각각 필요하다. 리스트를 반복하는 동안 두 리스트에서 사건과 확률을 하나씩 꺼내 곱하고 더하면 된다.
# 사건과 확률을 case와 prob 리스트에 저장한다.
case = [1, 2, 3, 4, 5, 6]
prob = [1/6, 1/6, 1/6, 1/6, 1/6, 1/6]
# 사건과 확률 리스트를 zip 함수로 묶어 for 루프로 반복한다. 반복하는 동안 두 리스트에서 값을 받아 변수 c와 p에 저장하고
# 곱한 결과를 ex 변수에 저장한다.
ex = 0.0
for c, p in zip(case, prob):
ex = ex + c*p
print(ex)
# ex = sum(c*p for c, p in zip(case, prob))
3.5
1.2 이동평균
- 이동평균은 자주 사용하는 평균이다. 기술적 분석에서도 5일 이동평균, 20일 이동평균, MACD등 여러 기술적 지표에 자주 사용한다.
이동평균은 계산에 들어가는 값 중 가장 오래된 값을 버리고 새로운 값을 추가한 뒤 새로운 평균을 구한다.
즉, 정지된 값이 아니라 새로운 데이터를 받아 그 대푯값을 업데이트한다.
# 이동평균
# 주가를 prices 리스트에 저장한다.
prices = [44800, 44850, 44600, 43750, 44000, 43900, 44350, 43530, 45500, 45700]
# 5일 이동평균
n = 5
# prices의 n번째 항목부터 마지막 항목까지 반복한다.
for p in prices[n:]:
# 항목 p의 index를 마지막 인덱스로 정한다.
end_index = prices.index(p)
# 마지막 인덱스에서 n만큼 앞에 있는 시작 인덱스를 정한다.
begin_index = end_index - n
# end_index와 begin_index를 계산해 가져올 위치를 확인한다.
print(begin_index, end_index)
print('\n')
# 계산한 end_index와 begin_index를 갖고 prices 리스트에서 다섯 개 항목을 확인한다.
for p in prices[n:]:
end_index = prices.index(p)
begin_index = end_index - n
print(prices[begin_index : end_index])
print('\n')
# 다섯 개씩 가져와서 sum() 함수로 합계를 구하고 n으로 나눠 이동평균을 계산한다.
for p in prices[n:]:
end_index = prices.index(p)
begin_index = end_index - n
print(sum(prices[begin_index : end_index]) / n)
0 5
1 6
2 7
3 8
4 9
[44800, 44850, 44600, 43750, 44000]
[44850, 44600, 43750, 44000, 43900]
[44600, 43750, 44000, 43900, 44350]
[43750, 44000, 43900, 44350, 43530]
[44000, 43900, 44350, 43530, 45500]
44400.0
44220.0
44120.0
43906.0
44256.0
1.3 가중(산술)평균
- 가중(산술)평균은 자료의 중요도나 영향 정도에 해당하는 가중치를 고려해 구한 평균값이다.
주식의 평균매입단가도 가중평균이다. - 재무 분야의 WACC(Weighted Average Cost of Capital)역시 가중평균이다.
WACC는 회사의 자본구조 중 부채와 지분의 시장가치를 바탕으로 한 가중평균이며 현금흐름을 할인하는 데 사용한다.
# 평가 점수와 평가 비중을 scores와 weight 리스트에 저장한다.
scores = [82, 95, 67]
weight = [0.3, 0.45, 0.25]
# scores와 weight 리스트를 zip 함수로 묶어 for 루프로 반복한다.
# wgt_avg 는 합계를 저장할 변수
wgt_avg = 0.0
# 반복하는 동안 변수 s와 w에 저장하고 곱셈의 결과를 합한다.
for s, w in zip(scores, weight):
wgt_avg = wgt_avg + s*w
print(wgt_avg)
# wgt_avg = sum(s*w for s, w in zip(scores, weight))
84.1
1.4 분산과 표준편차
- 금융에서 분산(variance)과 표준편차(standard deviation)는 리스크를 가리키는 척도다.
좀 더 일반적으로 설명하면 분산과 표준편차는 데이터의 흩어진 정도를 가리킨다.
평균과 기댓값이 데이터의 중심을 가리킨다면,
분산과 표준편차는 데이터들이 데이터의 중심에서 얼마나 흩어져 있는지를 설명하는 척도다.
- 편차(deviation)는 평균과의 차이인데, 편차를 구해보면 크기가 다른 편차가 여러 개 존재한다.
그런데, ‘편차가 얼마인가?’라는 질문을 받는다면 모든 편차를 다 말해줘야 한다.
그러므로 대푯값으로 편차 중 대표가 되는 표준을 정한다.
# 평균과 표준편차, 분산을 한번 계산해 보자.
# 분산을 계산할 리스트 nums를 준비한다.
nums = [1, 2, 3, 4, 5]
# 리스트의 평균을 계산한다.
avg = sum(nums) / len(nums)
# 리스트를 반복해 편차 제곱합을 계산한다.
sumsquare = 0.0
# nums 리스트를 반복하면서 n에 저장하고
for n in nums:
# 여기서 평균(avg)을 뺀 결과를 제곱해 합계를 구한다.
sumsquare = sumsquare + (n - avg) ** 2
var = sumsquare / (len(nums) - 1)
print(var)
# sumsquare = sum((n - avg) ** 2 for n in nums)
2.5
# 표준편차를 구하려면 sqrt() 함수가 필요하므로 math 모듈을 임포트 한다.
import math
stdev = math.sqrt(var)
print(stdev)
1.5811388300841898
1.5 정규분포에서 표준편차와 평균
- 표준편차, 평균과 밀접한 관계를 가진 것이 정규분포다.
일반적으로 종 모양의 정규분포에서 평균을 중심으로 평균 $\pm 1$ 표준편차 내 범위는 정규분포 면적의 대략 68%를 차지한다.- 모든 관측치의 약 68%는 평균으로부터 1 표준편차 이내에 속한다.
- 모든 관측치의 약 95%는 평균으로부터 2 표준편차 이내에 속한다.
- 모든 관측치의 약 99.7%는 평균으로부터 3 표준편차 이내에 속한다.
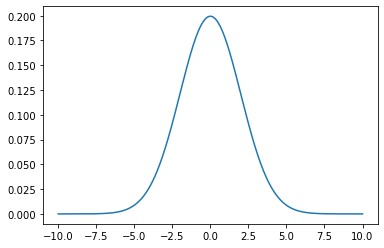
# -10 ~ 10 사이에서 평균이 0, 표준편차가 2인 정규분포를 그려보자.
# matplotlib, scipy 라이브러리를 임포트한다.
import matplotlib.pyplot as plt
from scipy.stats import norm
# x축은 -10 ~ 10 사이에서 0.001 간격으로 정한다.
x_axis = np.arange(-10, 10, 0.001)
# 평균 = 0, 표준편차 = 2.0 인 정규분포를 만든다.
plt.plot(x_axis, norm.pdf(x_axis, 0, 2))
plt.show()
1.6 자유도
- 분산 또는 표준편차를 계산할 때는 데이터가 모집단(population)인지 또는 표본(sample)인지에 따라 계산이 약간 달라진다.
- 모집단의 일부만을 대상으로 데이터를 구한다. 모집단의 일부를 표본집단이라고 한다. 전체가 아닌 일부이므로 통계량이 정확하지는 않다.
- 표본집단의 분산도 마찬가지다. 특히 표본집단의 분산 계산에 사용한 평균은 모집단의 평균이 아니다.
이러한 오차를 일부 보정하기 위해 $N-1$로 나눠준다. 수학적으로 말하면, 데이터가 표본집단일 때 $N-1$로
편차 제곱합을 나눠야 모집단 분산에 대한 불편추정량(unbiased estimator)이 되기 때문이다.
여기서, $N-1$을 자유도(degree of freedom)라고 한다.
1.7 공분산과 상관계수
1.7.1 공분산
- 두 변수의 상관관계를 나타내는 척도로 공분산과 상관계수가 있다. 공분산 수식(표본의 공분산)은 다음과 같다.
- 여기서 $x$와 $y$는 각각의 변수를 의미하고 $\mu$는 변수의 평균이다. 그리고 $n$은 데이터의 개수를 의미한다.
- 공분산에서 중요한 것은 부호뿐이다.
공분산이 (+)이면 $x$와 $y$는 양의 상관관계다. $x$가 증가하면 $y$도 증가한다는 의미다.
반대로 공분산이 (-)이면 $x$와 $y$는 음의 상관관계다. $x$가 증가하면 $y$는 감소한다는 의미다. - 이처럼 공분산은 $x$와 $y$변수 간의 방향성을 알려주지만 상관관계의 정도를 구체적으로 표현하지는 못한다.
1.7.2 상관계수
- 상관관계를 표준화한 값이 상관계수다. 표준화됐기 때문에 상관계수는 $-1 \sim 1$ 사이이므로 상관관계 비교가 가능하다.
상관계수는 $\rho (rho)$라고 표시하는데 공식은 다음과 같다.
- 상관계수는 두 변수 간의 관계를 의미한다. 그러나 두 변수 간의 연관된 정도를 나타낼 뿐 인과관계를 설명하는 것은 아니다.
두 변수 간의 인과관계는 회귀분석을 통해 확인할 수 있다. 보편적으로 많이 사용하는 상관계수는 피어슨 상관계수이다.
- 상관계수 $r$값은 $-1 \sim +1$ 사이의 값으로 $X$와 $Y$가 완전히 동일하면 +1, 전혀 다르면 0, 반대 방향으로 완전히 동일하면 -1이다.
$r^2$은 $X$로 부터 $Y$를 예측할 수 있는 정도를 의미하며, 이를 결정계수(coefficient of determination)라고 한다.
결정계수는 우리가 추정하는 선형 모델이 실제 데이터에 얼마나 잘 맞는지 알려주는 적합도를 나타내는 척도다.
# 상관계수를 계산하기 위한 필요한 함수들
import math
# 평균을 계산하는 함수
def mean(x):
return sum(x) / len(x)
# 두 리스트 곱의 합계
def sum_of_product(xs, ys):
return sum(x * y for x, y in zip(xs, ys))
# 제곱합을 계산하는 함수
def sum_of_squares(v):
return sum_of_product(v, v)
# 편차를 계산하는 함수
def deviation(xs):
x_mean = mean(xs)
return [x - x_mean for x in xs]
# 분산을 계산하는 함수
def variance(x):
n = len(x)
deviations = deviation(x)
return sum_of_squares(deviations) / (n - 1)
# 공분산을 계산하는 함수
def covariance(x, y):
n = len(x)
return sum_of_product(deviation(x), deviation(y)) / (n - 1)
# 표준편차를 계산하는 함수
def standard_deviation(x):
return math.sqrt(variance(x))
# 상관계수를 계산하는 함수
def correlation(xs, ys):
stdev_x = standard_deviation(xs)
stdev_y = standard_deviation(ys)
if stdev_x > 0 and stdev_y > 0:
return covariance(xs, ys) / (stdev_x * stdev_y)
else:
return 0 # 편차가 존재하지 않는다면 상관관계는 0
# x와 y 리스트와 correlation() 함수를 사용해 상관관계를 계산
x1 = [41, 45, 49, 32]
y1 = [66, 65, 89, 22]
x2 = [35, 88, 77, 45]
y2 = [22, 33, 44, 55]
x3 = [10, 95, 73, 76]
y3 = [8, 21, 57, 63]
print(correlation(x1, y1), '\n')
print(correlation(x2, y2), '\n')
print(correlation(x3, y3))
0.9710913019589138
0.0970411349395372
0.5234440434202298
# 위의 함수 전혀 필요없이 numpy의 corrcoef 함수를 사용하여 손쉽게 구할수도 있다.
print(np.corrcoef(x1, y1)[0, 1], '\n')
print(np.corrcoef(x2, y2)[0, 1], '\n')
print(np.corrcoef(x3, y3)[0, 1])
0.9710913019589138
0.09704113493953719
0.5234440434202297
Leave a comment