
AI Bootcamp Section1 Review4
Updated:

AI Bootcamp Section1 Review4
K-Means Clustering(K 평균 군집화)
Clustering은 가장 널리 알려진 비지도학습 중 한 가지 기법으로, 비슷한 유형의 데이터를 그룹화함으로써 unlabeled 데이터에 숨겨진 구조를 파악한다. 클러스터링을 응용하면 다음과 같은 것들을 구현할 수있다.
- 추천엔진 : 개인화된 사용자 경험을 제공하기 위해 삼품들을 그룹화 한다.
- 검색엔지 : 뉴스토픽들과 검색 결과를 그룹화 한다.
- 시장 세분화 : 지역, 인구, 행동 등을 바탕으로 고객으 그룹화 한다.
K-Means Clustering
K-Means 알고리즘은 가장 유명한 클러스터링 알고리즘이다. “K”는 주어진 데이터로부터 그룹화 할 그룹, 즉 클러스터의 수를 말한다. “Means”는 각 클러스터의 중심과 데이터들의 평균 거리를 의미한다. 이때 클러스터의 중심을 centroid라고 한다.
K-Means 알고리즘은 다음과 같은 과정으로 수행된다.
1. 데이터셋에서 K개의 centroids를 임의로 지정한다.
2. 각 데이터들을 가장 가까운 centroids가 속한 그룹에 할당한다.
3. 2번 과정에서 할당된 결과를 바탕으로 centroids를 새롭게 지정한다.
4. 2~3번 과정을 centroid가 더 이상 변하지 않을 때 까지 반복한다.
위 과정이 완려되면 unlabeled 데이터를 빠른 속도로 적절한 클러스터에 할당할 수 있다. 이번 포스팅에서는 scikit-learn라이브러리를 활용하여 구현하는 방법에 대해 알아보겠다.
Iris Dataset
scikit-learn에서 제공하는 데이터셋인 Iris(붓꽃)Dataset을 활용하도록 하겠다.
위 데이터셋은 붓꽃의 서로 다른 3가지종(setosa, versicolor, virginica)의 sepal(꽃받침), petal(꽃잎) feature를 포함하고 있다.
# scikit-learn 에서 제공하는 dataset 불러오기
from sklearn import datasets
iris = datasets.load_iris()
df_iris = iris.data
print(df_iris)
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]
[5.4 3.9 1.7 0.4]
[4.6 3.4 1.4 0.3]
[5. 3.4 1.5 0.2]
[4.4 2.9 1.4 0.2]
[4.9 3.1 1.5 0.1]
[5.4 3.7 1.5 0.2]
[4.8 3.4 1.6 0.2]
[4.8 3. 1.4 0.1]
[4.3 3. 1.1 0.1]
[5.8 4. 1.2 0.2]
[5.7 4.4 1.5 0.4]
[5.4 3.9 1.3 0.4]
[5.1 3.5 1.4 0.3]
[5.7 3.8 1.7 0.3]
[5.1 3.8 1.5 0.3]
[5.4 3.4 1.7 0.2]
[5.1 3.7 1.5 0.4]
[4.6 3.6 1. 0.2]
[5.1 3.3 1.7 0.5]
[4.8 3.4 1.9 0.2]
[5. 3. 1.6 0.2]
[5. 3.4 1.6 0.4]
[5.2 3.5 1.5 0.2]
[5.2 3.4 1.4 0.2]
[4.7 3.2 1.6 0.2]
[4.8 3.1 1.6 0.2]
[5.4 3.4 1.5 0.4]
[5.2 4.1 1.5 0.1]
[5.5 4.2 1.4 0.2]
[4.9 3.1 1.5 0.2]
[5. 3.2 1.2 0.2]
[5.5 3.5 1.3 0.2]
[4.9 3.6 1.4 0.1]
[4.4 3. 1.3 0.2]
[5.1 3.4 1.5 0.2]
[5. 3.5 1.3 0.3]
[4.5 2.3 1.3 0.3]
[4.4 3.2 1.3 0.2]
[5. 3.5 1.6 0.6]
[5.1 3.8 1.9 0.4]
[4.8 3. 1.4 0.3]
[5.1 3.8 1.6 0.2]
[4.6 3.2 1.4 0.2]
[5.3 3.7 1.5 0.2]
[5. 3.3 1.4 0.2]
[7. 3.2 4.7 1.4]
[6.4 3.2 4.5 1.5]
[6.9 3.1 4.9 1.5]
[5.5 2.3 4. 1.3]
[6.5 2.8 4.6 1.5]
[5.7 2.8 4.5 1.3]
[6.3 3.3 4.7 1.6]
[4.9 2.4 3.3 1. ]
[6.6 2.9 4.6 1.3]
[5.2 2.7 3.9 1.4]
[5. 2. 3.5 1. ]
[5.9 3. 4.2 1.5]
[6. 2.2 4. 1. ]
[6.1 2.9 4.7 1.4]
[5.6 2.9 3.6 1.3]
[6.7 3.1 4.4 1.4]
[5.6 3. 4.5 1.5]
[5.8 2.7 4.1 1. ]
[6.2 2.2 4.5 1.5]
[5.6 2.5 3.9 1.1]
[5.9 3.2 4.8 1.8]
[6.1 2.8 4. 1.3]
[6.3 2.5 4.9 1.5]
[6.1 2.8 4.7 1.2]
[6.4 2.9 4.3 1.3]
[6.6 3. 4.4 1.4]
[6.8 2.8 4.8 1.4]
[6.7 3. 5. 1.7]
[6. 2.9 4.5 1.5]
[5.7 2.6 3.5 1. ]
[5.5 2.4 3.8 1.1]
[5.5 2.4 3.7 1. ]
[5.8 2.7 3.9 1.2]
[6. 2.7 5.1 1.6]
[5.4 3. 4.5 1.5]
[6. 3.4 4.5 1.6]
[6.7 3.1 4.7 1.5]
[6.3 2.3 4.4 1.3]
[5.6 3. 4.1 1.3]
[5.5 2.5 4. 1.3]
[5.5 2.6 4.4 1.2]
[6.1 3. 4.6 1.4]
[5.8 2.6 4. 1.2]
[5. 2.3 3.3 1. ]
[5.6 2.7 4.2 1.3]
[5.7 3. 4.2 1.2]
[5.7 2.9 4.2 1.3]
[6.2 2.9 4.3 1.3]
[5.1 2.5 3. 1.1]
[5.7 2.8 4.1 1.3]
[6.3 3.3 6. 2.5]
[5.8 2.7 5.1 1.9]
[7.1 3. 5.9 2.1]
[6.3 2.9 5.6 1.8]
[6.5 3. 5.8 2.2]
[7.6 3. 6.6 2.1]
[4.9 2.5 4.5 1.7]
[7.3 2.9 6.3 1.8]
[6.7 2.5 5.8 1.8]
[7.2 3.6 6.1 2.5]
[6.5 3.2 5.1 2. ]
[6.4 2.7 5.3 1.9]
[6.8 3. 5.5 2.1]
[5.7 2.5 5. 2. ]
[5.8 2.8 5.1 2.4]
[6.4 3.2 5.3 2.3]
[6.5 3. 5.5 1.8]
[7.7 3.8 6.7 2.2]
[7.7 2.6 6.9 2.3]
[6. 2.2 5. 1.5]
[6.9 3.2 5.7 2.3]
[5.6 2.8 4.9 2. ]
[7.7 2.8 6.7 2. ]
[6.3 2.7 4.9 1.8]
[6.7 3.3 5.7 2.1]
[7.2 3.2 6. 1.8]
[6.2 2.8 4.8 1.8]
[6.1 3. 4.9 1.8]
[6.4 2.8 5.6 2.1]
[7.2 3. 5.8 1.6]
[7.4 2.8 6.1 1.9]
[7.9 3.8 6.4 2. ]
[6.4 2.8 5.6 2.2]
[6.3 2.8 5.1 1.5]
[6.1 2.6 5.6 1.4]
[7.7 3. 6.1 2.3]
[6.3 3.4 5.6 2.4]
[6.4 3.1 5.5 1.8]
[6. 3. 4.8 1.8]
[6.9 3.1 5.4 2.1]
[6.7 3.1 5.6 2.4]
[6.9 3.1 5.1 2.3]
[5.8 2.7 5.1 1.9]
[6.8 3.2 5.9 2.3]
[6.7 3.3 5.7 2.5]
[6.7 3. 5.2 2.3]
[6.3 2.5 5. 1.9]
[6.5 3. 5.2 2. ]
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]]
여기서 각 row는 하나의 데이터 sample을 나타내고. 각 column은 feature를 나타내며 순서대로 sepal length(꽃받침의 길이), sepal width(꽃받침의 넓이), petal length(꽃임의 길이), petal width(꽃잎의 넓이)를 의미한다. 이번 포스팅에서는 sepal length와 width두 가지 feature만을 고려하도록 하겠다. 데이터로부터 feature만을 뽑아내어 산점도를 그려보도록 하겠다.
import matplotlib.pyplot as plt
x1 = df_iris[:, 0]
y1 = df_iris[:, 1]
plt.scatter(x1, y1, alpha = 0.4, color = '#1687a7')
plt.xlabel('sepal length(cm)')
plt.ylabel('sepal width(cm)')
plt.show();
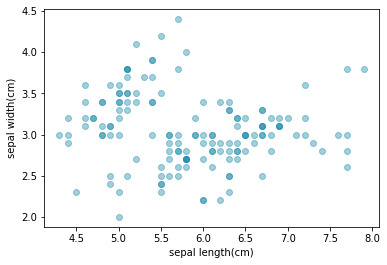
scatter plot 을 보니 그룹화 되어 있지 않고 그냥 한가지의 그룹으로 되어있는것을 색으로 알 수 있다.
# K-Means import
from sklearn.cluster import KMeans
- K-Means로 모델을 생성할때, 클러스터링 하려는 그룹의 수 k를 지정해줘야 한다.
이는n-clusters옵션으로 지정할수 있다.
# 3개의 그룹으로 클러스터링
k = 3
model = KMeans(n_clusters = k)
- 다음으로
.fit()메서드를 통해 K-Mean 클러스터링을 수행할 수 있습니다.
model.fit(df_iris)
KMeans(n_clusters=3)
- K-Means 를 수행한 다음,
.predict()메서드를 통해 unlabeled 데이터를 그룹에 할당할 수 있다.
labels = model.predict(df_iris)
labels
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 2, 2, 2, 2, 0, 2, 2, 2,
2, 2, 2, 0, 0, 2, 2, 2, 2, 0, 2, 0, 2, 0, 2, 2, 0, 0, 2, 2, 2, 2,
2, 0, 2, 2, 2, 2, 0, 2, 2, 2, 0, 2, 2, 2, 0, 2, 2, 0])
x = df_iris[:, 0]
y = df_iris[:, 1]
plt.scatter(x, y, alpha = 0.4, c = labels)
plt.xlabel('sepal length(cm)')
plt.ylabel('sepal width(cm)')
plt.show();
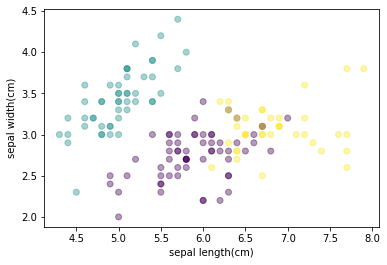
처음 scatter plot은 한가지의 색으로 그룹화 되어 있지 않았는데, 간단한 K-Means로 clustering을 하여, 3가지 색으로 그룹화가 잘 이루어 진것을 볼 수 있다.
하지만 이것이 잘 분류가 되었는지 궁금하다. 확인을 한번 해보겠다.
- 잘 분류된 그룹이란?
일단 그룹에 포함된 각 데이터 포인트들이 뭉쳐져 있을 경우 좋은 그룹이라고 말할 수 있다. 그룹에 포함된 데이터들이 퍼져있는 정도를 inertia라고 하는데, inertia는 각 클러스터의 중심인 centroid 와 각 데이터들 사이의 거리를 나타낸다. 즉, inertia가 낮은 그룹을 좋은 그룹이라고 할 수 있고, 이러한 그룹을 적게 만들수록 좋은 모델이라고 할 수 있다.
num_clusters = list(range(1, 11))
intertias = []
# 각 K별로 모델을 생성하여 inertia를 측정
for i in num_clusters:
model = KMeans(n_clusters = i)
model.fit(df_iris)
intertias.append(model.inertia_)
# K에 따른 interia의 변화 시각화
plt.plot(num_clusters, intertias, '-o')
plt.xlabel('Number of Clusters')
plt.ylabel('Intertia')
plt.title('The Elbow Method showing the optimal k')
plt.show();
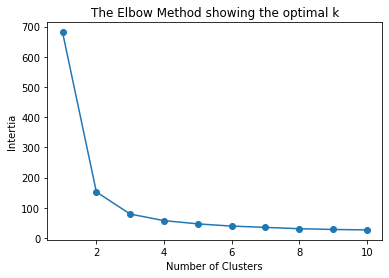
일반적으로 클러스터의 수가 증가할 수록 inertia는 감소하게 된다. 우리의 목표는 inertia를 최소화 시키면서 동시에 클러스터의 수를 최소화 시키는 것이다. 즉 inertia가 감소하는 정도가 낮아지는 지점을 찾으면 된다. 위 그래프에서는 3 이 가장 최적의 클러스터의 수 라고 말할 수 있다.

Leave a comment