
AI Bootcamp Section1 Review2
Updated:

AI Bootcamp Section1 Review2
2. Statistics(Hypothesis Test)
- week2에서는 통계학을 배웠는데 그 중에서도 가설검정 하는걸 위주로 배웠기 때문에 소제목을 Hypothesis Test라고 지었다.
그중에서도 특히 One-sample t-test, Two-sample t-test, anova, One-sample Chi-square test, Two-sample Chi-square test, Bayesian
정도가 중요하다고 생각이 들기 때문에 그중에서도 이해가 잘 가지 않은 부분에 대해 포스팅 하겠다.
1) One-sample t-test
- 전체 학생들 중 20명의 학생들을 추려 키를 재서 전체 학생들의 평균 키가 175cm인지 아닌지 알아보고 싶다.
$H_0$ : 학생들의 평균 키가 175cm이다.
$H_1$ : 학생들의 평균 키가 175cm가 아니다.
import numpy as np
from scipy import stats
#to get consistent result
np.random.seed(1)
#generate 20 random heights with mean of 180, standard deviation of 5
heights= [180 + np.random.normal(0,5)for _ in range(20)]
#perform 1-sample t-test
tTestResult1 = stats.ttest_1samp(heights,175)
#histogram
import seaborn as sns
import matplotlib.pyplot as plt
sns.distplot(heights, kde=False, fit=sp.stats.norm)
plt.show();
#print result
print("The T-statistic is %.3f and the p-value is %.3f" % tTestResult1)
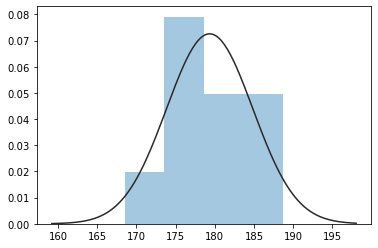
The T-statistic is 3.435 and the p-value is 0.003
- p-value 가 0.003으로, 기각역을 p < 0.05로 설정했을 때 귀무 가설을 기각한다.
즉, 귀무 가설이 참일때 (학생들의 실제 평균 키가 175cm일때) 위와 같은 표본을 얻을 확률이 0.003으로,
학생들의 평균 키는 175cm가 아니라고 할 수 있다.
2) Two-sample t-test
#perform 2-sample t-test
tTestResult2= stats.ttest_ind(heights,175)
#histogram
import seaborn as sns
import matplotlib.pyplot as plt
sns.distplot(heights, kde=False, fit=sp.stats.norm)
plt.show();
#print result
print("The T-statistic is %.3f and the p-value is %.3f" % tTestResult2)
The T-statistic is nan and the p-value is nan
3) ANOVA
두 개 이상의 집단에 대해 평균비교를 하고자 할 때 기존의 t-test를 사용한다면, 두 집단씩 짝을 지어 t-test를 진행해야 함
- 세 개의 집단이 있을 때, 둘씩 짝을 짓는 경우의 수: 3가지
- 네 개의 집단이 있을 때, 둘씩 짝을 짓는 경우의 수: 6가지
- 다섯 개의 집단이 있을 때, 둘씩 짝을 짓는 경우의 수: 10가지
- 여섯 개의 집단이 있을 때, 둘씩 짝을 짓는 경우의 수: 15가지
- t-test로만 진행한다면, 분석횟수가 기하급수적으로 증가함
⇒ 과잉검증의 문제가 발생함
ANOVA에서 사용하는 용어
- 요인(factor): 집단을 구별하는 (독립)변수를 분산분석의 맥락에서는 “요인”이라고 칭함. 예) 성별, 국가
- 수준(level): 요인의 수준. 즉, 각 집단을 의미함. 예) 요인이 “성별”일 때, 수준은 “남”, “여”
- 상호작용: 한 요인의 수준에 따른 종속변수의 차이가 또 다른 요인의 수준에 따라 달라질 때, “요인들 간 상호작용이 존재한다”고 함
일원분산분석
$H_0$ : 모든 집단의 평균이 동일하다.
$H_1$ : 적어도 한 집단의 평균이 다른 집단들과 다르다.
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/Liam427/stuydy-data/main/data/PlantGrowth.csv')
df.head()
| weight | group | |
|---|---|---|
| 0 | 4.17 | ctrl |
| 1 | 5.58 | ctrl |
| 2 | 5.18 | ctrl |
| 3 | 6.11 | ctrl |
| 4 | 4.50 | ctrl |
df.group.unique()
array(['ctrl', 'trt1', 'trt2'], dtype=object)
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
model = ols('weight ~ C(group)', df).fit()
anova_lm(model)
| df | sum_sq | mean_sq | F | PR(>F) | |
|---|---|---|---|---|---|
| C(group) | 2.0 | 3.76634 | 1.883170 | 4.846088 | 0.01591 |
| Residual | 27.0 | 10.49209 | 0.388596 | NaN | NaN |
- Pr(>F)가 p-value. 이 값이 0.05보다 작으면 통계적으로 유의미한 차이가 있음.
- 위의 예시에서는 0.0159로 0.05보다 작음. 따라서 유의미한 차이.
- 구체적으로 어떤 수준(집단)이 차이가 있는지 확인하려면 사후분석(post hoc tests)
- 유의미한 차이가 없는 경우에는 사후분석할 필요가 없음
다원분산분석
- 집단을 구분하는 변수(즉, 요인)이 두 개일 때 이원분산분석(two-way ANOVA)라 함
- 요인이 세 개이면, 삼원분산분석(three-way ANOVA)라 함
- 일반적인 표현으로, 요인이 n개 일 때, n원분산분석(n-way ANOVA)라고 함
- 다원분산분석을 실시하는 주요 목적 중 하나는 요인 간 상호작용을 파악하기 위함임
dat = pd.read_csv('https://raw.githubusercontent.com/Liam427/stuydy-data/main/data/poison.csv', index_col=0)
dat.head()
| time | poison | treat | |
|---|---|---|---|
| 1 | 0.31 | 1 | A |
| 2 | 0.45 | 1 | A |
| 3 | 0.46 | 1 | A |
| 4 | 0.43 | 1 | A |
| 5 | 0.36 | 2 | A |
# 이 데이터에서 종속변수는 time, 독립변수는 poison과 treat이다.
# poison 요인으로 구분한 집단별 표본수는 모두 16으로 동일
dat.groupby('poison').agg(len)
| time | treat | |
|---|---|---|
| poison | ||
| 1 | 16.0 | 16 |
| 2 | 16.0 | 16 |
| 3 | 16.0 | 16 |
# treat 요인구분한 집단별 표본수는 모두 12으로 동일
dat.groupby('treat').agg(len)
| time | poison | |
|---|---|---|
| treat | ||
| A | 12.0 | 12 |
| B | 12.0 | 12 |
| C | 12.0 | 12 |
| D | 12.0 | 12 |
# poison과 treat 요인으로 구분한 각 집단별 표본수는 모두 4로 동일
dat.groupby(['poison', 'treat']).agg(len)
| time | ||
|---|---|---|
| poison | treat | |
| 1 | A | 4.0 |
| B | 4.0 | |
| C | 4.0 | |
| D | 4.0 | |
| 2 | A | 4.0 |
| B | 4.0 | |
| C | 4.0 | |
| D | 4.0 | |
| 3 | A | 4.0 |
| B | 4.0 | |
| C | 4.0 | |
| D | 4.0 |
model = ols('time ~ C(poison) * C(treat)', dat).fit()
anova_lm(model)
| df | sum_sq | mean_sq | F | PR(>F) | |
|---|---|---|---|---|---|
| C(poison) | 2.0 | 1.033012 | 0.516506 | 23.221737 | 3.331440e-07 |
| C(treat) | 3.0 | 0.921206 | 0.307069 | 13.805582 | 3.777331e-06 |
| C(poison):C(treat) | 6.0 | 0.250138 | 0.041690 | 1.874333 | 1.122506e-01 |
| Residual | 36.0 | 0.800725 | 0.022242 | NaN | NaN |
- poison: F(2, 36) = 23.222, p < 0.05로 유의미. 즉 poison의 수준에 따라 평균에 차이가 난다고 볼 수 있음
- treat: F(3, 36) = 13.806, p < 0.05로 유의미. 즉 treat의 수준에 따라 평균에 차이가 난다고 볼 수 있음
- poison:treat: F(6, 36) = 1.874, p > 0.05로 유의미하지 않음. 상호작용 효과는 발견하지 못함
4) One-sample Chi-square test
- 적합성검정
$H_0$ : 관찰빈도 = 기대빈도
$H_1$ : 관찰빈도 ≠ 기대빈도
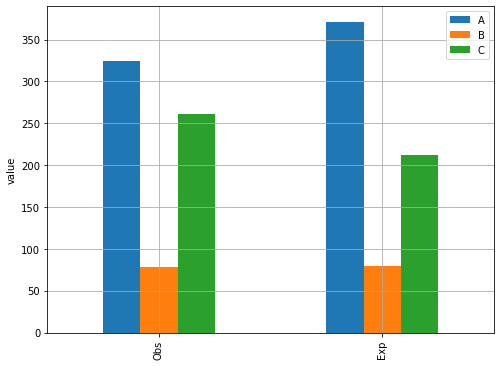
# 관찰빈도
xo = [324, 78, 261]
# 기대빈도
xe = [371, 80, 212]
dfx = pd.DataFrame([xo, xe],
columns = ['A','B','C'],
index = ['Obs', 'Exp'])
dfx
| A | B | C | |
|---|---|---|---|
| Obs | 324 | 78 | 261 |
| Exp | 371 | 80 | 212 |
# bar plot
ax = dfx.plot(kind='bar', figsize=(8,6))
ax.set_ylabel('value')
plt.grid(color='darkgray')
plt.show();
# 카이제곱 통계량
from scipy.stats import chisquare
chiresult = chisquare(xo, f_exp=xe)
chiresult
Power_divergenceResult(statistic=17.329649595687332, pvalue=0.00017254977751013492)
- p-value가 0.0001725로 유의수준 0.05보다 아주 작으므로 귀무가설을 기각하고, 대립가설을 지지한다.
5) Two-sample Chi-square tes
xf = [269, 83, 215]
xm = [155, 57, 181]
xdf = pd.DataFrame([xf, xm],
columns = ['item1','item2','item3'],
index = ['Female','Male'])
xdf
| item1 | item2 | item3 | |
|---|---|---|---|
| Female | 269 | 83 | 215 |
| Male | 155 | 57 | 181 |
- 독립성 검정
$H_0$: 성별과 아이템 품목 판매량은 관계가 있다.
$H_1$: 성별과 아이템 품목 판매량은 관계가 없다.
from scipy.stats import chi2_contingency
chi_2, p, dof, expected = chi2_contingency([xf, xm])
msg = 'Test Statistic: {}\np-value: {}\nDegree of Freedom: {}'
print(msg.format(chi_2, p, dof))
print(expected)
Test Statistic: 7.094264414804222
p-value: 0.028807134195296135
Degree of Freedom: 2
[[250.425 82.6875 233.8875]
[173.575 57.3125 162.1125]]
- p-value는 0.02881으로 유의수준 0.05보다 작은 값이므로 귀무가설을 기각한다.
- 따라서 성별과 아이템 품목 판매량은 관계가 없다.
6) Bayesian
베이지안 방법(Bayesian method)은 현대 데이터 과학에 사용되는 방법론 중 하나로 예측, 추론 등 많은 작업에서 문제를 해결하는데 사용된다.
-
베이지안 확률론(Bayesian probability)은 확률을 ‘지식 또는 믿음의 정도를 나타내는 양’으로 해석하는 확률론이다.
베이즈 추론(Bayesian inference)은 통계적 추론의 한 방법으로, 추론 대상의 사전 확률과 추가적인 정보를 통해 해당 대상의 사후 확률을 추론하는 방법으로 불확실성을 유지한다는 점에서 기존의 전통적인 통계적 추론과 다르다. - 베이지안 추론과 관련된 개념을 간략하게 정리하면 다음과 같다.
- 베이지안 추론은 간단히 말해 새로운 증거를 본 뒤 믿음을 업데이트 하는 것이다.
- 베이지안 세계관에서 확률은 사건에서 믿을 수 있는 정도를 계량한 척도, 즉 사건 발생을 얼마나 자신하는가로 해석
- 베이지안에서 우리는 사건 A에 대한 우리의 믿음의 양을 P(A)로 표시하고 이를 사전확률이라고 한다.
-
업데이트된 믿음, P(A X)는 증거 X가 주어진 상황에서 A의 확률로 볼 수 있다. 이를 사후확률이라고 한다. - 빈도주의자의 추정은 변동성이 크고, 신뢰 구간이 더 넓은 반면, 베이지안은 사전확률을 도입하고 확률을 돌려줌으로써 불확실성을 유지한다.
- 사전확률과 사후확률과 관련된 베이즈 정리는 다음과 같다.
-
$P(A X) =\frac {P(X A)P(A)}{P(X)}$
-

Leave a comment