
AI Bootcamp 열여덟번째
Updated:

열여덟번째 Diary
Linear Regression
Codestates에서 이번 section에서는 머신러닝, 딥러닝을 배우게 되었다.
그러면서 처음으로 어제 오늘 linear regression 우리말로 선형회귀분석에 대해서 배웠다. 짤막하게 예제를 통해서 남겨보려 한다.
선형회귀는 데이터를 가장 잘 설명할수 있는 직선을 찾아내는 것이다.
직선은 $y = \alpha x + \beta$와 같이 일차 함수로 나타낼수 있는데,
결국 가장 적합한 기울기 $\alpha$와 $x$절편 $\beta$를 찾아 내는 것이다.
물론, 이것은 특성이 하나인 경우 simple linear regression 을 말하는 것이고,
특성이 두개 이상이면 multiple linear regressiond이며,
그에따라 $x$가 많아 지면서 설명이 된다.
mlearn에서 간단한 데이터 하나를 불러와서, 그중 랜덤하게 75%의 샘플을 선택해서 훈련셋으로 나머지 25%는 테스트셋으로 분리해준다.
훈련셋을 이용해서 선형 회귀 모델을 훈련함으로 최적의 $\alpha$와 $\beta$를 구한다.
그 다음에 $y = \alpha x + \beta$함수에서 테스트셋의 각 샘플들의 특성값을 $x$에 대입시켜 주면 그 샘플의 타겟값에 대핸 예측값을 알수 있다.
타겟값과 예측값의 상관성을 결정계수를 통해 평가한다.
결정계수는 1에 가까울 수록 예측이 정확하다는 의미이다.
# library import
import mglearn
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# wave data set 은 회귀 알고리즘을 설명하기 위해 인위적으로 만든 데이터셋으로
# 입력 특성 하나와 모델링할 타깃변수를 가진다.
# 특성을 x축에 놓고 회귀의 타겟을 y출에 놓는다.
X, y = mglearn.datasets.make_wave(n_samples = 60)
# 데이터셋을 train set과 test set으로 분리 한다.
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
# train data $ test data plot
plt.plot(X_train, y_train, '*')
plt.plot(X_test, y_test, 'o', color = '#ffc478')
plt.xlabel('Feature')
plt.ylabel('Target')
plt.grid(True)
plt.show();
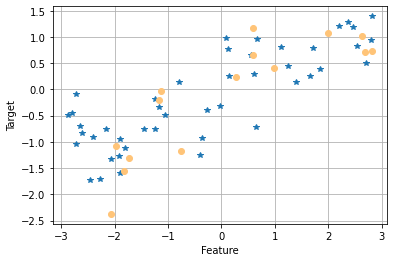
# train linear regressor
mlr = LinearRegression().fit(X_train, y_train)
# 훈련으로 찾아낸 최적의 𝛼
print('𝛼 = {}'.format(mlr.coef_))
# 훈련으로 찾아낸 최적의 𝛽
print('𝛽 = {}'.format(mlr.intercept_))
𝛼 = [0.39390555]
𝛽 = -0.031804343026759746
# test set 의 데이터들의 타겟값 예측
y_pred = mlr.predict(X_test)
# train set coefficient
print("training set score: {:.2f}".format(mlr.score(X_train, y_train)))
# test set coefficient
print("test set score: {:.2f}".format(mlr.score(X_test, y_test)))
training set score: 0.67
test set score: 0.66
plt.plot(X_test, y_pred, color = '#eb596e')
plt.plot(X_train, y_train, '*')
plt.plot(X_test, y_test, 'o', color = '#ffc478')
plt.xlabel('Feature')
plt.ylabel('Target')
plt.grid(True)
plt.show();
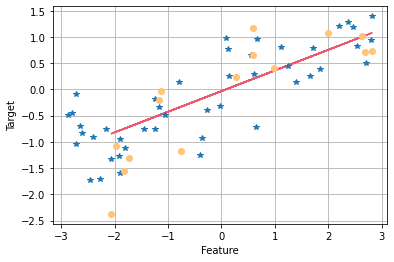
- 파랑색 * 는 train data이고, 노랑색 o 는 test data이고, 빨강색 직선은 훈련으로 찾은 최적의 직선이다.
- 선형회귀 모델은 train set을 이용해서 $y = 0.3939x - 0.0318$이라는 일차함수를 찾아냈다. (위 그래프에서 빨간선이 바로 그 일차함수이다.) 이 일차함수에 train set의 특성값과 test set의 특성값을 각각 대입한 다음에, 결정계수(coefficient)를 구했더니 train set의 coefficient는 0.67이었고, test set의 coefficien는 0.66이었다. test set의 coefficient가 0.66이므로 성능이 엄청 나쁜 것은 아니지만 그렇다고 좋은 것도 아니다. 예측 성능이 충분히 좋진 않다는 뜻이다. 그러나 train set의 coefficient와 큰 차이가 없는 것은 좋은 일이다. train set에 과대적합(overfitting)이 되지 않았고, 오히려 과소적합(underfitting)인 상황이기 때문이다. 가장 좋은 결과는 test set 점수와 train set 점수가 모두 1에 가깝고, 둘의 차이가 적은 경우이다.
특히, 지금의 wave data set 은 회귀 알고리즘을 설명하기 위해 인위적으로 만든 데이터셋이므로 아마 그 성능이 더욱이 깨끗하게 나온 것으로 보인다. 계속 공부 해 나갈수록 이렇게 정리 할 공간에도 심도깊은 데이터를 가져와 포스팅 하는 날이 하루 빨리 왔으면 좋겠다.

Leave a comment